




Nvidia hat bei den MLPerf Inference v6.0-Tests, die als Referenz für KI-Leistungsmessungen gelten, mit seiner Blackwell Ultra-Architektur der nächsten Generation seine Stärke unter Beweis gestellt. Den veröffentlichten Ergebnissen zufolge erzielte Blackwell Ultra eine deutliche Überlegenheit gegenüber allen Wettbewerbern. Nvidia hebt sich insbesondere durch die höchste KI-Produktionskapazität (AI factory throughput) und die niedrigsten Token-Kosten ab.
Die Version 6.0 von MLPerf bietet einen wesentlich größeren Umfang als vorherige Versionen. Das von MLCommons entwickelte neue Testpaket unterstützt aktuelle Modelle wie DeepSeek-R1, GPT-OSS-120B und Mixtral 8x7B. Gleichzeitig deckt es verschiedene Workloads wie dichte große Sprachmodelle (LLM), generative Empfehlungssysteme und Vision-Language-Modelle ab. Somit prüft der Test nicht nur die Hardwareleistung, sondern die gesamte Systemintegrität.
Leistungssteigerung nicht nur durch Hardware
Die Daten zeigen, dass Nvidia nicht nur hardwareseitig, sondern auch bei Software-Optimierungen erhebliche Fortschritte gemacht hat. Das Unternehmen konnte die Token-Generierungsgeschwindigkeit im Vergleich zum Beginn der DeepSeek-R1-Tests um das 2,7-Fache steigern, ohne die Hardware zu verändern. Dies verdeutlicht den kritischen Einfluss von Software- und Systemoptimierungen auf die Gesamtleistung.
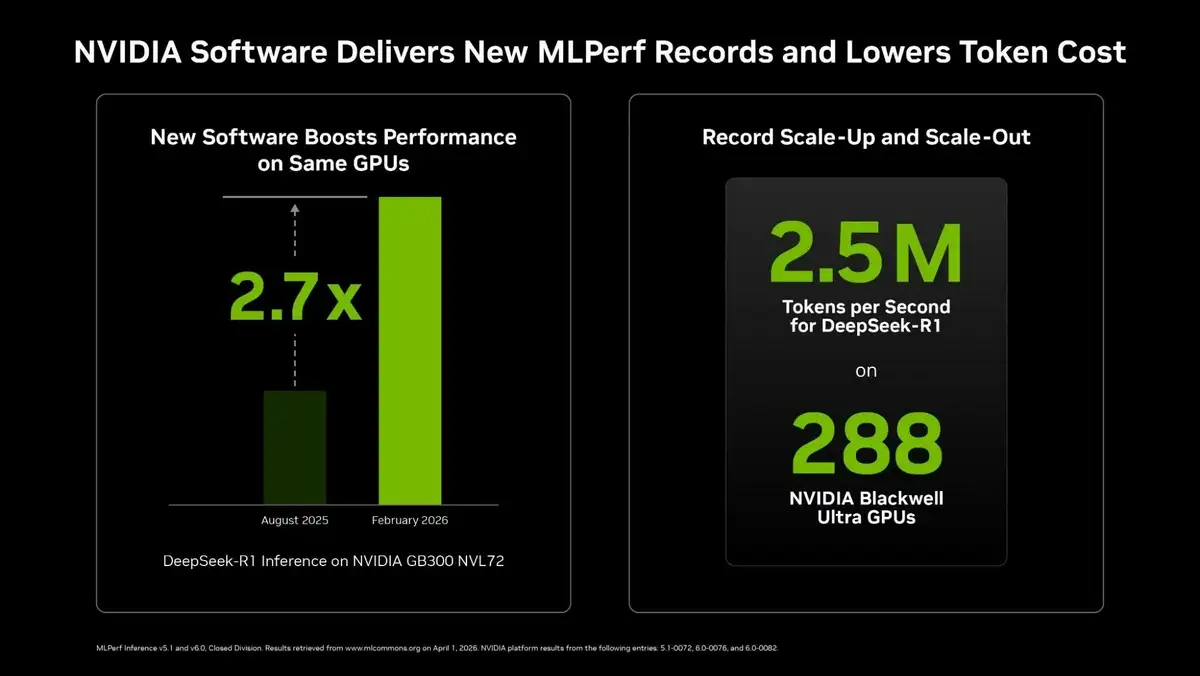
Auf der Hardwareseite ist die Leistung von Blackwell Ultra bemerkenswert. Es wird angegeben, dass im Vergleich zur vorherigen GB200 NVL72-Plattform von Nvidia eine bis zu 2,77-fache Geschwindigkeitssteigerung erzielt wurde. Dies zeigt, dass die neue Architektur nicht nur theoretisch, sondern auch in der Praxis erhebliche Vorteile bietet.
Bis zu 9-mal höhere Leistung
Nach den von Nvidia geteilten Daten erreichte das Unternehmen in den MLPerf Inference-Tests eine bis zu 9-mal höhere Leistung als der nächste Wettbewerber. Dieser Unterschied, der besonders in der Metrik Token/Sekunde/GPU sichtbar wird, stellt einen entscheidenden Vorteil für KI-Systeme dar, die auf Rechenzentrumsebene arbeiten.
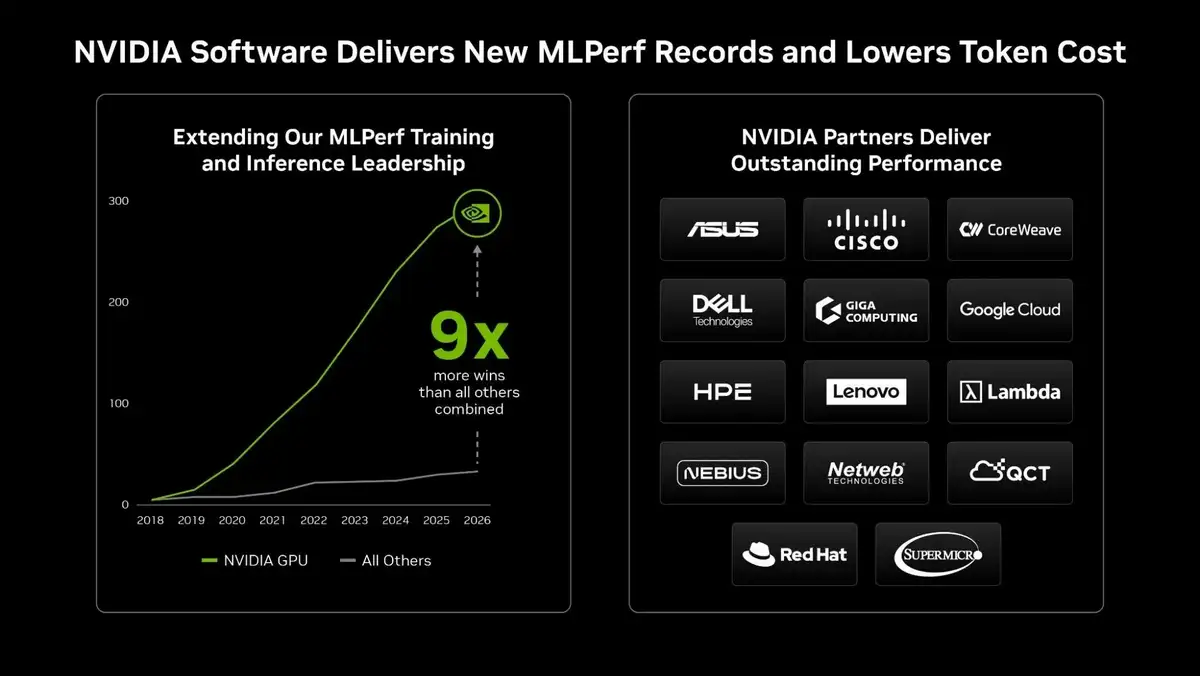
Das Unternehmen betont zudem, dass es im vergangenen Jahr die einzige Firma war, die DeepSeek-R1-Ergebnisse im Rahmen von MLPerf Inference veröffentlicht hat, und diese Führungsposition mit der neuen Version behauptet. Hinter dem Erfolg von Nvidia steht ein End-to-End-Designansatz: Alle Komponenten, vom Chipdesign über die Systemarchitektur bis hin zur Rechenzentrumsinfrastruktur und dem Software-Stack, werden gemeinsam optimiert.
Wie schneidet AMD ab?

AMD nahm ebenfalls mit den Instinct MI355X GPUs an MLPerf Inference v6.0 teil und erzielte beeindruckende Ergebnisse, insbesondere bei der Multinode-Skalierung. In Tests mit den Modellen Llama 2 70B und GPT-OSS-120B überschritt AMD die Marke von 1 Million Token pro Sekunde und demonstrierte damit eine leistungskonforme Produktion. Die MI355X erzielte im Single-Node-Betrieb wettbewerbsfähige Ergebnisse gegenüber B200- und B300-GPUs und bot bei der Multinode-Skalierung eine Effizienz von 93-98 %.


