



Trotz der rasanten Fortschritte im Bereich der künstlichen Intelligenz in den letzten Jahren hat sich gezeigt, dass aktuelle High-End-Modelle unter komplexen und ungeordneten realen Bedingungen immer noch anfällig sind. Ein neues technisches Dokument des chinesischen Technologiegiganten Tencent betont, dass KI-Systeme gravierende Einschränkungen beim „In-Context Learning“ aufweisen, was sich direkt auf die praktische Anwendung auswirkt.

Menschen lernen sofort, Modelle versuchen sich zu erinnern
Forscher argumentieren, dass das „In-Context Learning“ in den Mittelpunkt des Modelldesigns gestellt werden muss, damit KI-Modelle künftig über kontrollierte Umgebungen hinauswachsen können. Laut den Forschern können aktuelle Systeme Aufgaben nicht konsistent erfüllen, da sie den Kontext nicht korrekt interpretieren können, obwohl sie Zugriff auf die erforderlichen Informationen haben.
Die Studie erläutert den grundlegenden Unterschied zwischen Menschen und KI anhand von Alltagsbeispielen. Dass ein Softwareentwickler die Dokumentation für ein ihm unbekanntes Tool schnell scannt und mit dem Debugging beginnt, ein Spieler ein neues Spiel durch Lesen des Regelwerks lernt oder ein Wissenschaftler durch die Analyse hunderter Versuchsprotokolle eine neue Beziehung entdeckt, wird als konkretes Beispiel für diesen Unterschied angeführt.
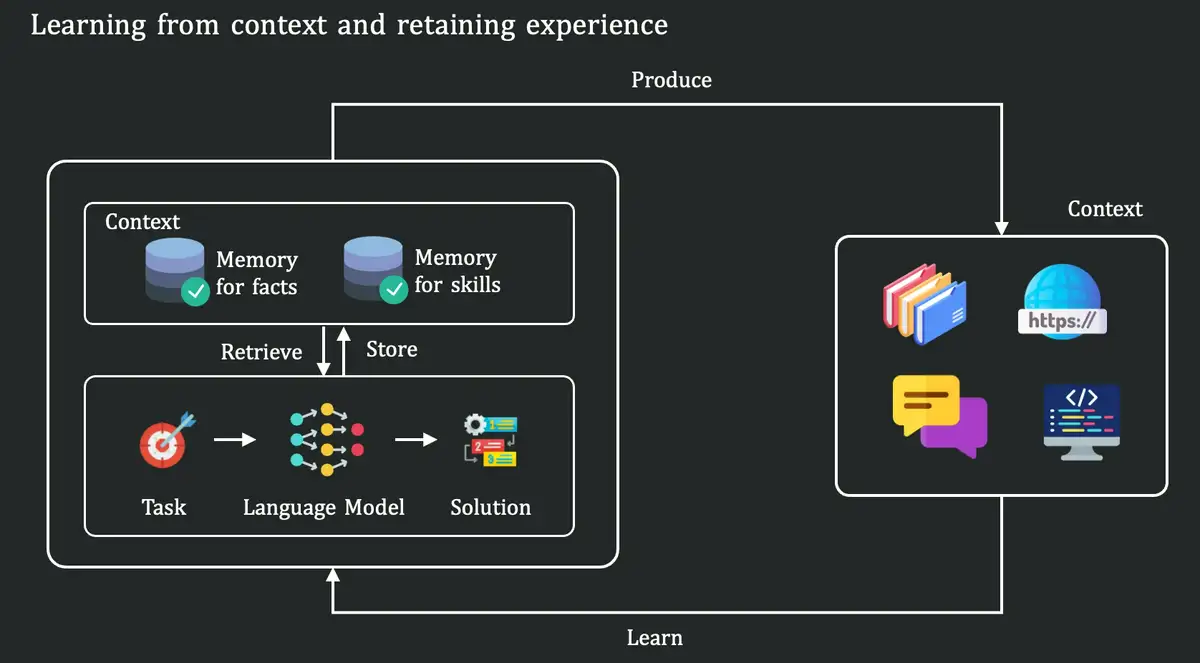
Laut Tencent lernen Menschen in diesen Prozessen nicht auf Basis von in der Vergangenheit auswendig gelerntem Wissen, sondern basierend auf dem Kontext, dem sie in diesem Moment begegnen. Im Gegensatz dazu rufen aktuelle große Sprachmodelle (LLMs) hauptsächlich Informationen ab, die während des Vortrainings in ihre Parameter eingebettet wurden. In der Inferenzphase verlassen sie sich auf ihr statisches internes Gedächtnis, anstatt aktiv neue Informationen zu lernen.
In der Studie wird dies als „strukturelle Inkompatibilität“ bezeichnet. Modelle sind darauf optimiert, über Dinge nachzudenken, die sie bereits wissen. Nutzer benötigen jedoch Systeme, die Probleme lösen können, die von ständig wechselnden und verstreuten Kontexten abhängen.
Neuer Standard zur Messung von Kontext-Lernen entwickelt
Um dieses Problem zu messen, entwickelte das Tencent-Forschungsteam ein neues Bewertungskriterium namens CL-bench. Insgesamt 19 führende KI-Modelle wurden anhand von 500 komplexen Kontexten, 1.899 Aufgaben und 31.607 Validierungskriterien getestet. Diese Aufgaben zielen darauf ab, die Fähigkeit der Modelle zum „Learning on the Job“ zu messen, also die Fähigkeit, Bedeutungen aus einem gegebenen Kontext zu extrahieren und sich an neue Situationen anzupassen.
Im Gegensatz zu klassischen Benchmarks, die auf Wissensfragen basieren, stellt CL-bench jedem Task seinen eigenen Kontext zur Verfügung. Dieser Ansatz kommt der menschlichen Lernweise grundsätzlich näher. Zudem sollte dies nicht mit kontinuierlichen Lernmodellen verwechselt werden. Während ein Modell dort seine eigenen Gewichte ständig aktualisiert, bleiben beim In-Context Learning die Grundparameter unverändert.
Durchschnittliche Erfolgsquote bei 17 Prozent
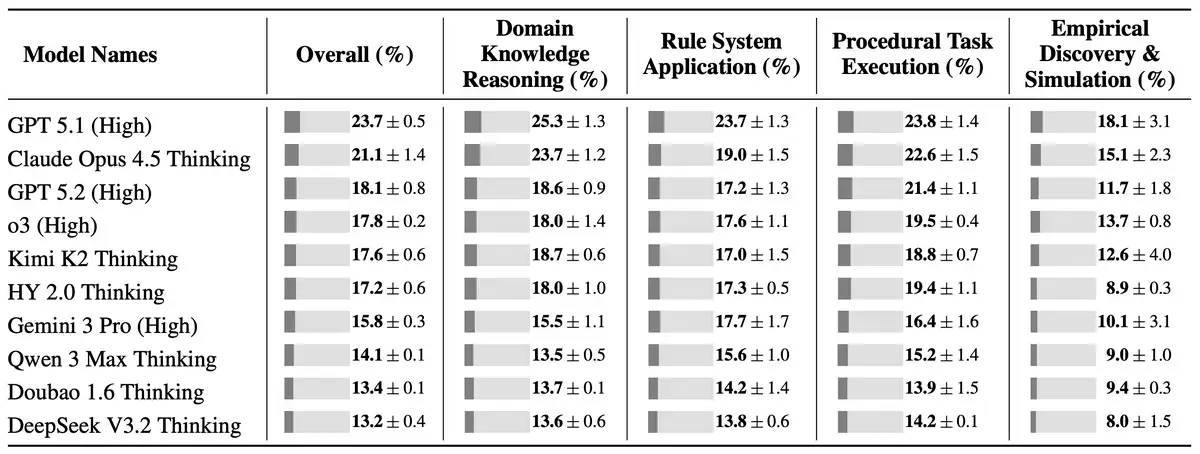
Die Testergebnisse zeigen deutlich, wie sehr sich die KI in der Komplexität der realen Welt verliert. Die durchschnittliche Erfolgsquote der Top-10-Modelle bei CL-bench lag bei lediglich 17,2 Prozent. Die Studie betont, dass aktuelle Modelle noch weit davon entfernt sind, zuverlässige Kontext-Lerner zu sein.
Auf der anderen Seite erzielte das GPT-5.1-Modell von OpenAI mit 23,7 Prozent die höchste Punktzahl, gefolgt vom Claude Opus 4.5-Modell von Anthropic mit 21,1 Prozent. Die beste Leistung unter den in China entwickelten Modellen erbrachte das Kimi K2-Modell von Moonshot AI auf dem fünften Platz mit 17,6 Prozent. Tencents eigenes Modell Hunyuan 2.0 belegte mit 17,2 Prozent den sechsten Platz.
Selbst das erfolgreichste GPT-5.1-Modell konnte weniger als 1 Prozent der Aufgaben lösen, wenn überhaupt kein Kontext bereitgestellt wurde.
Die Forschung prognostiziert, dass sich die Mensch-KI-Beziehung ändern wird, wenn sich das Kontext-Lernen verbessert. Demnach könnten Menschen von Datenlieferanten zu „Kontext-Providern“ werden, die den genauesten und reichhaltigsten Kontext entwerfen.
Hier gibt es jedoch ein kritisches Problem. Laut Tencent ist In-Context Learning ein temporärer Prozess. Das Modell vergisst das Gelernte, sobald sich das Kontextfenster schließt. Die eigentliche große Frage lautet: Wie kann das aus dem Kontext gewonnene Wissen dauerhaft gemacht werden? Dies bedeutet ein tieferes Lernen, das nicht nur Fakten, sondern auch Fähigkeiten, Erfahrungen und Muster umfasst.
Die CL-Bench-Plattform ist über GitHub oder Hugging Face zugänglich.


