




Google hat offiziell die neue Generation seiner Open-Weights-Modellfamilie, Gemma 4, angekündigt, die auf Gemini 3-Technologien basiert. Der bemerkenswerteste Wandel ist diesmal jedoch nicht nur technischer Natur, sondern betrifft auch eine grundlegende Transformation der Lizenzierung.
Vier verschiedene Modelle verfügbar
Die neue Gemma 4-Familie besteht aus vier verschiedenen Modellen, die auf unterschiedliche Hardware-Leistungsstufen zugeschnitten sind. Die für ressourcenbeschränkte Geräte entwickelten „Effective“-Modelle mit 2 Milliarden (E2B) und 4 Milliarden (E4B) Parametern zielen speziell auf Smartphones und eingebettete Systeme ab. Für leistungsstärkere Systeme stehen ein Mixture of Experts (MoE)-Modell mit 26 Milliarden Parametern und ein Dense-Modell mit 31 Milliarden Parametern zur Verfügung.
Laut technischen Details von Google erreicht das 26B MoE-Modell eine hohe Geschwindigkeit, indem es während der Inferenz nur 3,8 Milliarden Parameter aktiv nutzt. Dieser Ansatz ermöglicht eine höhere Token-Generierungsrate im Vergleich zu Modellen ähnlicher Größe. Das 31B Dense-Modell hingegen konzentriert sich eher auf maximale Genauigkeit und Qualität als auf reine Geschwindigkeit.
Die großen Modelle sind theoretisch so konzipiert, dass sie im bfloat16-Format auf einer einzelnen 80GB Nvidia H100 GPU laufen können. Bei einer Quantisierung mit geringerer Präzision passen sie auch auf Consumer-Grafikkarten.
Fokus auf lokale Ausführung
Eines der entscheidendsten Merkmale von Gemma 4 ist die deutlich verbesserte Fähigkeit zur Ausführung auf lokaler Hardware. Google gibt an, sich besonders auf die Reduzierung von Latenzzeiten konzentriert zu haben. Laut Unternehmensaussagen wurde bei den kleinen Modellen ein Niveau von „nahezu null Latenz“ erreicht.
Die E2B- und E4B-Modelle wurden durch die Zusammenarbeit mit Qualcomm und MediaTek für Geräte wie Smartphones, Raspberry Pi und Jetson Nano optimiert. Diese Modelle verbrauchen weniger Speicher und Akku als die Vorgängergeneration.
Unterstützung für über 140 Sprachen
Die gesamte Gemma 4-Familie ist nicht nur auf Text beschränkt. Die Modelle können Bilder und Videos verarbeiten, was ihren Einsatz in Bereichen wie OCR (optische Zeichenerkennung) und Grafikanalyse stärkt. Die kleineren Modelle bieten zudem Unterstützung für Audio-Input und Spracherkennung.
Google gibt an, dass die Modelle in über 140 Sprachen trainiert wurden und große Kontextfenster bieten. Die Edge-Modelle unterstützen 128.000 Token, während die großen Modelle ein Kontextfenster von 256.000 Token besitzen.
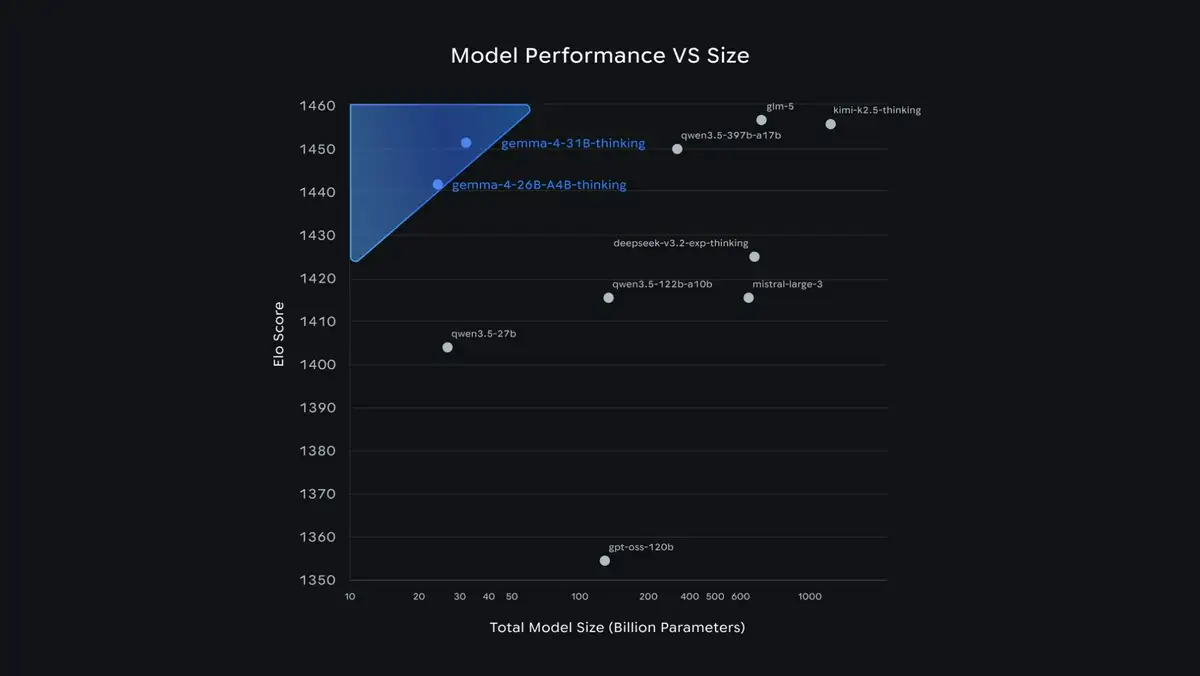
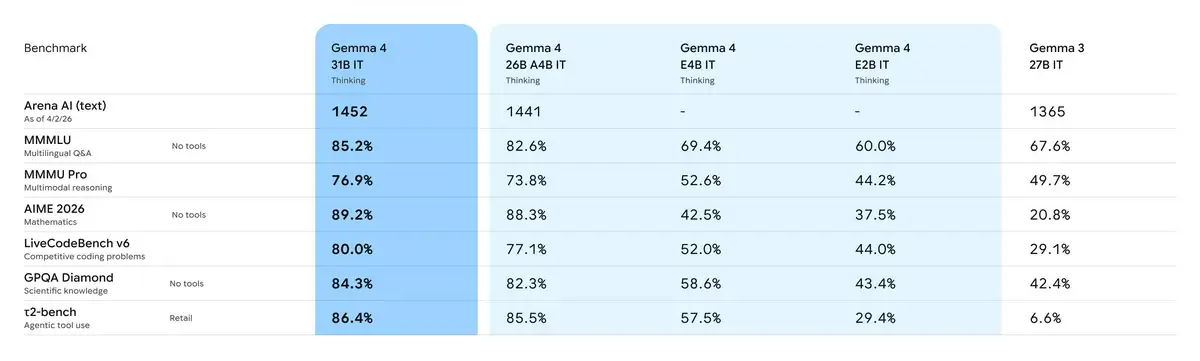
Eine der ehrgeizigsten Behauptungen von Google ist, dass Gemma 4 einen signifikanten Sprung in der „Intelligenz pro Parameter“ gemacht hat. Laut den geteilten Daten belegte das 31B-Modell den dritten Platz und das 26B-Modell den sechsten Platz im Arena AI-Ranking. Diese Leistung ist bemerkenswert, da sie Modelle übertrafen, die bis zu 20-mal größer sind.
Gemma 4 bietet zudem Verbesserungen in den Bereichen logisches Denken, Mathematik und Befolgen von Anweisungen auf Gemini 3-Niveau. Darüber hinaus wurde die Familie durch Funktionen wie native Funktionsaufrufe, strukturierte JSON-Ausgabe und API-Integrationen für agentische Workflows vorbereitet.
Zusätzlich kann die neue Modellfamilie Code ohne Internetverbindung generieren. Google betont, dass insbesondere die großen Varianten von Gemma 4 bei entsprechender Hardware Code in einer Qualität produzieren können, die cloudbasierten Lösungen nahekommt.
Wechsel zur Apache 2.0-Lizenz
Die vielleicht wichtigste Änderung ist nicht technischer, sondern rechtlicher Natur. Google hat die umstrittene Speziallizenz früherer Gemma-Versionen aufgegeben und ist zur Apache 2.0-Lizenz gewechselt.
Mit diesem Schritt können Entwickler die Modelle nun frei modifizieren, in kommerziellen Projekten verwenden und sie uneingeschränkt in ihrer eigenen Infrastruktur oder in der Cloud verbreiten.
Gemma 4-Modelle können ab sofort über Hugging Face, Kaggle und Ollama heruntergeladen werden. Zudem sind sie über die Google AI Studio und AI Edge Gallery Plattformen testbar. Für die lokale Nutzung optimiert, können die Modelle bei Bedarf auch kostenpflichtig über die Google Cloud betrieben werden.


